Ces définitions ont été rédigées à partir de la version anglaise de DataSuds.
Les traductions françaises du vocabulaire sont mentionnées après les mots anglais en italique au début de chaque définition.
Les impressions d’écran sont également celles de la version anglaise.
Sommaire
Qu’est-ce qu’un dataverse ?
Le mot “dataverse” désigne à la fois le nom donné
- à l’outil de gestion de données qui permet le partage, l’organisation, l’archivage, la pérennisation des données : on l’écrira alors « Dataverse », avec un D majuscule;
- aux répertoires, aux collections qui peuvent contenir des jeux de données (datasets / ensembles ou jeux de données) mais aussi d’autres dataverses : on l’écrira alors « dataverses », avec un d minuscule.
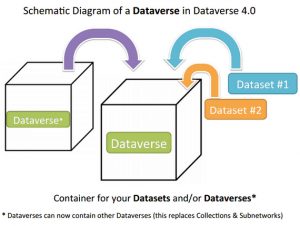
Un dataverse peut contenir autant de dataverses et/ou de datasets que l’on souhaite. On peut emboîter les dataverses les uns dans les autres (comme des dossiers et sous-dossiers). Par contre, un dataset ne peut pas contenir de dataverse.
Un dataset ne peut être publié (=rendu public) s’il est contenu dans un dataverse non publié. Toutefois, Dataverse propose de publier les deux en même temps lorsqu’on tente de publier un dataset contenu dans un dataverse non encore publié.
Un dataverse non publié peut être supprimé à tout moment.
Un dataverse publié ne peut être supprimé s’il contient un dataset déjà publié. On peut toutefois rendre inaccessible l’ensemble de ses contenus.
La figure suivante est un schéma illustratif de l’organisation de dataverse :
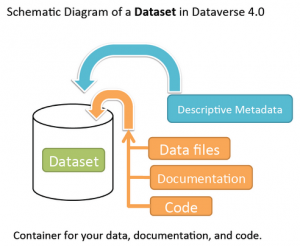
Qu’est-ce qu’un dataset / ensemble ou jeu de données ?
Un dataset (jeu de données ou ensemble de données en français) est un ensemble cohérent de données produites dans le cadre d’un même projet, sur un même objet d’étude et/ou recueillies sur un même lieu. Toutes les données d’un dataset peuvent donc être décrites avec une majorité de métadonnées communes.
Il comprend des datafiles (fichiers de données), mais aussi le code, la documentation et les métadonnées associées (le Plan de Gestion de Données, par exemple).
Tous les types de fichiers sont admis (tabulaire, texte, pdf, image, vidéo, audio, SHP, etc.), mais on choisira de préférence des formats ouverts et standards pour faciliter la réutilisation.
Les formats tabulaires RData, SPSS, STATA, CSV, XLSX seulement (xls n’est pas supporté) sont spécifiquement traités pour faciliter l’accès à leurs métadonnées internes et la visualisation de leur contenu.
Un dataset peut être composé d’une centaine de fichiers, sa taille pouvant atteindre quelques dizaines de gigaoctets.
La taille d’un fichier est limitée à 1 Go dans DataSuds : si cette limite vous pose problème, contactez-nous.
Un dataset non publié peut être supprimé à tout moment.
Un dataset publié ne peut plus être supprimé mais on peut rendre ses fichiers inaccessibles.
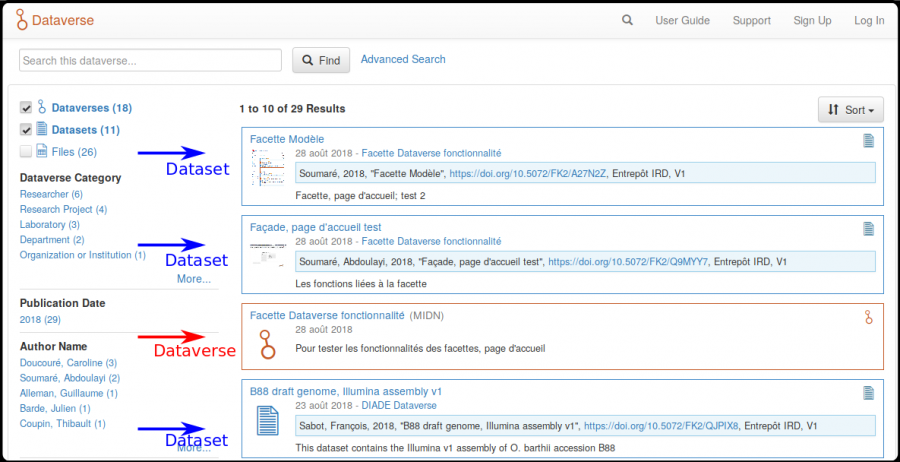
Dans Dataverse, les dataverses, les datasets et les datafiles se distinguent visuellement par les icônes et les couleurs utilisées :

Dans un listing, les dataverses sont encadrés en rouge, les datasets en bleu et les datafiles en gris.
Qu’est-ce qu’un template ?
Un template est un modèle de saisie de datasets ou jeux de données. Il peut comporter des métadonnées du modèle générique et des champs de saisie pré-remplis.
La création du template est un droit associé à la création du dataverse : toute personne qui peut créer un dataverse peut également créer un template associé.
Un template se crée au niveau d’un dataverse et pourra être utilisé dans tous ses sous-dataverses.
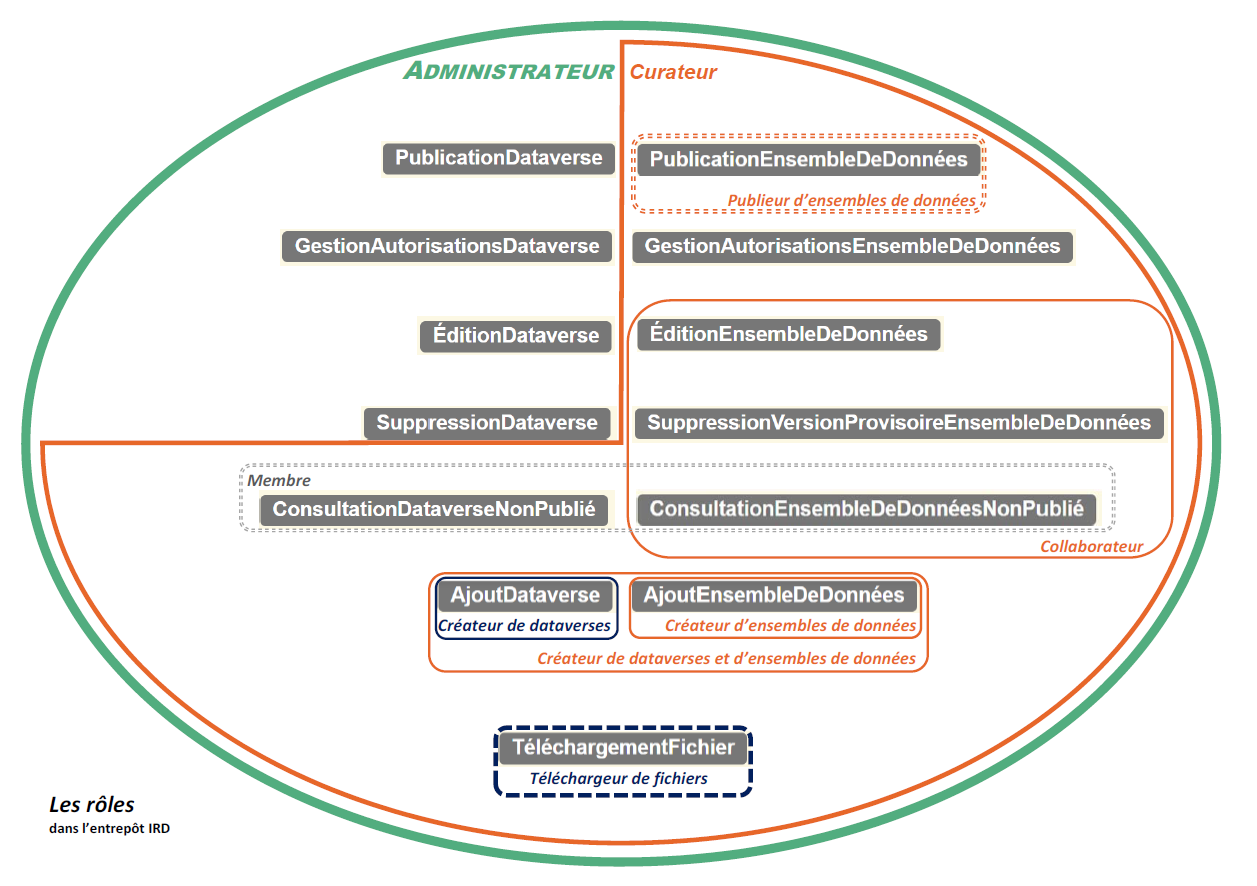
Utilisateurs, groupes, rôles et permissions : gestion des droits
Un utilisateur est une personne physique qui s’est connectée au moins une fois à la plateforme.
Il est défini par une adresse mail, un identifiant et un mot de passe.
L’entrepôt est accessible à tous mais les utilisateurs peut utiliser des fonctionnalités supplémentaires et avoir accès à des données non publiques.
Un groupe est un ensemble d’utilisateurs.
Les groupes peuvent être imbriqués : dans ce cas le groupe de plus haut niveau contient l’ensemble des utilisateurs de ses groupes enfants.
2 groupes sont définis par défaut :
-
AllUsers: tous les utilisateurs, y compris les internautes non authentifiés (anonymes), -
Authenticated-users: tous les utilisateurs identifiés (accès anonyme exclu).
Un rôle est un ensemble prédéfini de permissions d’effectuer certaines actions sur un dataverse, un dataset ou un fichier.
Lors de la création d’un dataverse, ce nouveau dataverse n’hérite pas des rôles de son contenant. Le créateur du dataverse aura le rôle “Admininstrateur”.
Lors de la création d’un dataset, le nouveau dataset n’hérite pas des rôles de son contenant. Le créateur du dataset aura le rôle “Curateur” ou “Collaborateur” selon ses droits dans le dataverse contenant.
Un rôle peut être attribué à un groupe comme à un utilisateur.
Il existe 2 types de rôles :
-
les “rôles système” définis par le super administrateur, utilisables partout;
-
les “rôles dataverse” définis par un gestionnaire de dataverse, au niveau de ce dataverse.
Dans Dataverse, les permissions sont les suivantes :
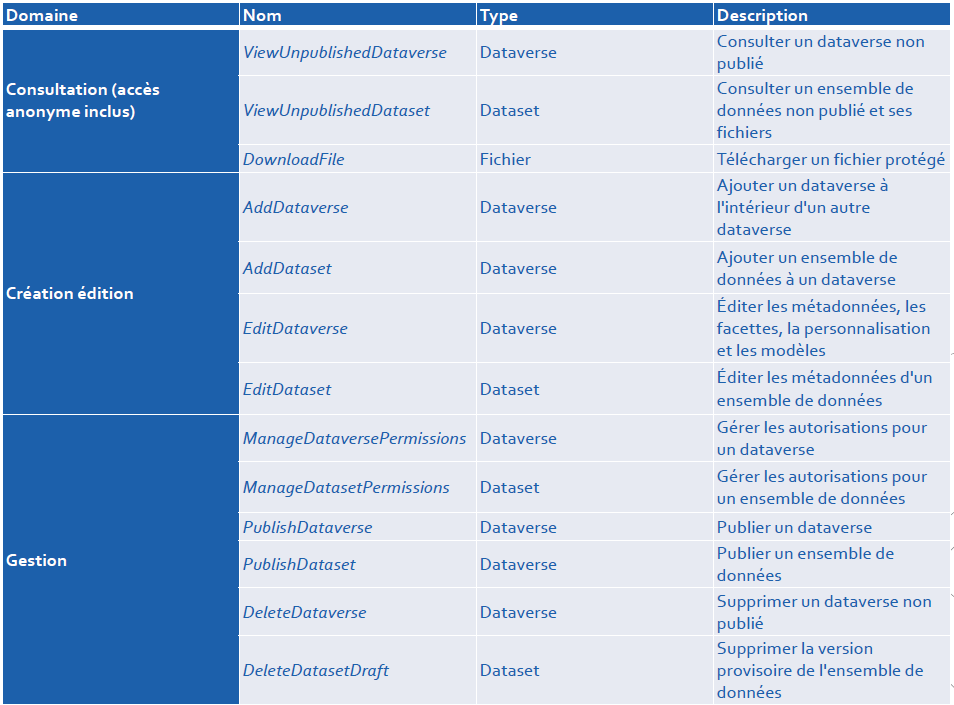
Dans DataSuds, les rôles définis sont les suivants (en italique) :